Building an open-source version of Antithesis, Part 1: Understanding the deterministic simulation testing ecosystem
Understanding deterministic simulation testing and laying out the foundations for our implementation
Introduction ¶
You might be wondering, what’s Antithesis? This is what they describe themselves as (from their website):
Antithesis is a continuous reliability platform that autonomously searches for problems in your software within a simulated environment. Every problem we find can be perfectly reproduced, allowing for efficient debugging of even the most complex problems.
The people behind Antithesis are the ones who pioneered DST (deterministic simulation testing) at FoundationDB. But what’s deterministic simulation testing?
To some, DST is a superpower. But for others, it just looks like some variant of automated testing. I’ll take a neutral stance here, and I’ll try to explain it without hyping it up.
As a developer, you likely won’t have the superpower to predict what might break your code. Not everything is observable, and it is very likely that your code might encounter a few “unknown-unknowns” in its lifetime.
Most systems are non-deterministic in nature. Every execution of your program is affected by external factors like clocks/timers, schedulers, networks, certain CPU instructions, etc., which introduce non-determinism.
Testing these systems can be a challenge. Traditional testing methods like unit/integration tests are limited in their ability to reproduce bugs. Some teams might have the resources to model and verify their systems through formal verification, but others likely won’t have the time and resources to follow the path of formal verification.
This is where DST (deterministic simulation testing) steps in. The best case study is FoundationDB, which I’ll be covering later in this article.
To understand DST, I encourage you to listen to Antithesis’ founder Will Wilson’s talk at StrangeLoop 2014, because he explains it better than I ever could.
But if you’re lazy, here’s a short description: DST involves running your code on a single-threaded simulator, where most external interfaces that introduce non-determinism are mocked to make it deterministic. The simulator then tries to find bugs through injecting multiple faults, and these bugs can be reproduced deterministically based on the seed used for the run.
Isn’t this fault injection or chaos engineering? Well.. technically yes (to some extent), but where DST shines is that it allows for advancing time just like how time advancement works in DES (discrete event simulation). Discrete-event simulation (DES) models the operations of a system as a sequence of events in time, where each event occurs at a particular point in time, and marks a change of state in the system. One could say DST is an extended version of DES, but I’ll leave the interpretation up to the reader.
With the advantage of time advancement, you can simulate years of system behavior in shorter periods of time, which makes it highly effective for understanding system behavior and uncovering issues that become visible after a certain period of time has elapsed.
Another advantage of utilizing deterministic simulation testing is that since most interfaces like networks are mocked, this reduces the amount of time required to process that operation.1
But the catch here is that your system needs to be deterministic to utilize deterministic simulation testing properly. FoundationDB, TigerBeetle and others have been able to utilize DST due to their design decisions, as they focused on making their systems deterministic.
Not everyone has the time or interest in rewriting their systems to be deterministic in nature. And some don’t want to deal with the overhead that DST brings, in terms of increased integration effort and design challenges, and I feel that it’s completely fine given that we live in an era where most systems are getting pointless integrations (psst, AI).
But what about those who want to integrate DST in their workloads but don’t have the resources to do so?
Antithesis tries to solve this problem. People who want to reap the benefits of deterministic simulation testing can do it with minimal changes to their current systems with the Antithesis platform. To use Antithesis, you just need to package your apps as containers, add some configuration and a workload to test on, and let Antithesis run the tests2. For obvious reasons, it’s a paid platform, but I’m not sure if it’s affordable enough for the general audience.
Why do I want to build one? ¶
But even before all that, you might be thinking about the goal of this project. Why do I even want to work on an open-source version?
There are two primary reasons behind it:
- As a learning exercise. Antithesis has a team full of talented engineers who have experience working in this space for almost 10 years. I definitely won’t be able to come close to their implementation, but even if I come close to a working prototype, I’d say that would be a huge achievement for me.
- No individual sign-up available.
- Antithesis currently doesn’t have an option to sign up as a single user, the only way right now to sign up is to contact their sales team. (However, if you’re a maintainer of an open-source project, they’ll try to test your code for free. 3)
- So, I decided that building an open-source version would be the best bet, and even though it’s easier said than done, it’s better to actively work on an OSS/free version for competitiveness.
I know that this is an ambitious project, and it’s likely that a working prototype would take years of development. But I also want to try experimenting without worrying about the fact that I’m trying to emulate the efforts of a team of experienced engineers who took ~6 years to build Antithesis.
For now, as a starting point, I’m trying to understand the various systems that utilize deterministic simulation testing. I’ll discuss the ones I know below in some detail.
FoundationDB (popular!) ¶
If you’re reading this article, then you might already know about FoundationDB. But if you don’t, then you might be interested in knowing their approach towards building resilient systems.
FoundationDB is a fault-tolerant key-value database which got acquired by Apple in 2015. It’s widely known for its emphasis on testing which is described in detail here and in their paper. I highly recommend reading both! (those are some of my favorites in my reading list)
To summarize, they first built an actor model on top of C++ called Flow (even before they wrote their database). Through Flow, they were able to abstract various actions of the database into a bunch of actors, which can be scheduled by Flow’s runtime. As a result of modeling their logic into an actor-based programming model, they were able to easily integrate it with their deterministic simulator. There’s a lot more to it, and I’ll try to cover it in the upcoming posts.
Here’s a HN comment (2013) from the founder about how Flow came into existence before FoundationDB:
We knew this was going to be a long project so we invested heavily in tools at the beginning. The first two weeks of FoundationDB were building this new programming language to give us the speed of C++ with high level tools for actor-model concurrency. But, the real magic is how Flow enables us to use our real code to do deterministic simulations of a cluster in a single thread.
As the first step3, the simulator will initialize a random seed like this (if not provided through the CLI):
// https://github.com/apple/foundationdb/blob/f27bc4ac2ba78de23e062ecfb3e8bc9a304e0c6e/fdbserver/fdbserver.actor.cpp#L1070
uint32_t randomSeed = platform::getRandomSeed();
The simulator will then try to run the specified workload inside the simulated cluster where network, disk, time, etc. are mocked to remove non-determinism. Here’s how a workload (or a test file) looks like:
# https://github.com/apple/foundationdb/blob/f27bc4ac2ba78de23e062ecfb3e8bc9a304e0c6e/tests/fast/AtomicBackupCorrectness.toml
[[test]]
testTitle = 'BackupAndRestore'
clearAfterTest = false
simBackupAgents = 'BackupToFile'
[[test.workload]]
testName = 'AtomicOps'
nodeCount = 30000
transactionsPerSecond = 2500.0
testDuration = 30.0
[[test.workload]]
testName = 'BackupAndRestoreCorrectness'
backupAfter = 10.0
restoreAfter = 60.0
backupRangesCount = -1
[[test.workload]]
testName = 'RandomClogging'
testDuration = 90.0
[[test.workload]]
testName = 'Rollback'
meanDelay = 90.0
testDuration = 90.0
[[test.workload]]
testName = 'Attrition'
machinesToKill = 10
machinesToLeave = 3
reboot = true
testDuration = 90.0
[[test.workload]]
testName = 'Attrition'
machinesToKill = 10
machinesToLeave = 3
reboot = true
testDuration = 90.0
This is a test composed of smaller workloads like RandomClogging (packet transfer delays/pauses, or simply, messing with the network), Attrition (kill/reboot machines), etc.
Since the simulator is deterministic, you can use the same seed which was generated at the start of the test to reproduce the bug that occurred.
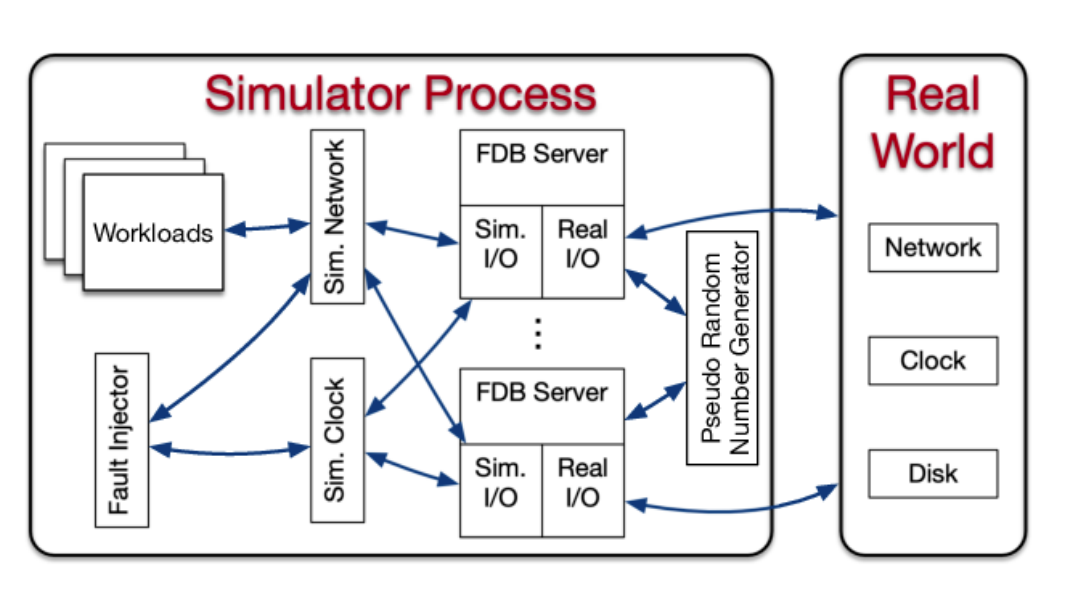
Another strategy used by FoundationDB is to extensively use their BUGGIFY macros4, which helps the simulator in finding more interesting edge cases which might lead to bugs. These macros are only enabled when they’re run in the simulator.
A few examples can be seen here, this one tries to tweak server knobs:
// https://github.com/apple/foundationdb/blob/f27bc4ac2ba78de23e062ecfb3e8bc9a304e0c6e/fdbclient/ServerKnobs.cpp#L556
init( ROCKSDB_ENABLE_CHECKPOINT_VALIDATION, false ); if ( randomize && BUGGIFY ) ROCKSDB_ENABLE_CHECKPOINT_VALIDATION = deterministicRandom()->coinflip();
and here the BUGGIFY macro is used inside a test workload for randomly closing connections:
// https://github.com/apple/foundationdb/blob/main/fdbserver/workloads/HTTPKeyValueStore.actor.cpp#L286-L291
// sometimes randomly close connection anyway
if (BUGGIFY_WITH_PROB(0.1)) {
ASSERT(self->conn.isValid());
self->conn->close();
self->conn.clear();
}
I personally like this approach of introducing failures through code and assisting the simulator, instead of letting the simulator trying to find interesting execution paths on its own.
TigerBeetle ¶
TigerBeetle’s simulator called VOPR (Viewstamped Operation Replicator)5, tries to spawn a cluster consisting of multiple servers and clients interacting with each other. All types of I/O is mocked out, and the entire simulation runs as a single process.
Network faults and delays are introduced through the network simulator. Here’s an example of network fault injection:
// https://github.com/tigerbeetle/tigerbeetle/blob/0277b9bf4e29443e12bae4cfed36f8306c721ef0/src/testing/packet_simulator.zig#L366
if (self.options.node_count > 1 and self.should_partition()) {
self.auto_partition_network();
Storage faults are introduced through the in-memory storage simulator. Here’s how TigerBeetle tries to corrupt sectors:
// https://github.com/tigerbeetle/tigerbeetle/blob/0277b9bf4e29443e12bae4cfed36f8306c721ef0/src/testing/storage.zig#L222
/// Cancel any currently in-progress reads/writes.
/// Corrupt the target sectors of any in-progress writes.
pub fn reset(storage: *Storage) void {
log.debug("Reset: {} pending reads, {} pending writes, {} pending next_ticks", .{
storage.reads.len,
storage.writes.len,
storage.next_tick_queue.count,
});
while (storage.writes.peek()) |_| {
const write = storage.writes.remove();
if (!storage.x_in_100(storage.options.crash_fault_probability)) continue;
// Randomly corrupt one of the faulty sectors the operation targeted.
// TODO: inject more realistic and varied storage faults as described above.
const sectors = SectorRange.from_zone(write.zone, write.offset, write.buffer.len);
storage.fault_sector(write.zone, sectors.random(storage.prng.random()));
}
Another nifty feature is their state checker which checks all state transitions of the replicas. The checksums are based on AEGIS-128L and are constructed here.
// https://github.com/tigerbeetle/tigerbeetle/blob/0277b9bf4e29443e12bae4cfed36f8306c721ef0/src/simulator.zig#L327C9-L331C49
const commits = simulator.cluster.state_checker.commits.items;
const last_checksum = commits[commits.len - 1].header.checksum;
for (simulator.cluster.aofs, 0..) |*aof, replica_index| {
if (simulator.core.isSet(replica_index)) {
try aof.validate(last_checksum);
And since the VOPR is completely deterministic, we can replay a bug using a seed, similar to the one we saw in FoundationDB.
Turmoil (Tokio) ¶
Tokio announced Turmoil last year and it has been on my radar for a while, but I haven’t seen a lot of projects using it6.
Turmoil tries to simulate hosts, networks and time. I’m not sure if they simulate disks, but this is in contrast to the previous approaches (FoundationDB, TigerBeetle, etc.) as the idea here is that you can import turmoil as a Rust crate and write your simulation tests.
The implementation is a bit similar to TigerBeetle’s simulator implementation:
// https://github.com/tokio-rs/turmoil/blob/766108f2e48bc54092955fc374fed2e0a15505f6/src/sim.rs#L137
pub fn crash(&mut self, addrs: impl ToIpAddrs) {
self.run_with_hosts(addrs, |addr, rt| {
rt.crash();
tracing::trace!(target: TRACING_TARGET, addr = ?addr, "Crash");
});
}
// https://github.com/tokio-rs/turmoil/blob/766108f2e48bc54092955fc374fed2e0a15505f6/src/sim.rs#L367
let World {
rng,
topology,
hosts,
..
} = world.deref_mut();
topology.deliver_messages(rng, hosts.get_mut(&addr).expect("missing host"));
There’s a RNG (random number generator), network mocks, etc. embedded into the simulator. On each tick, it performs operations like message delivery, etc. Nothing novel here, but that doesn’t discredit the work done to implement it. I still feel that it’s great of the Tokio team to make this open source in order to help other Rust users.
Coyote ¶
Coyote is another library which can be used to test C# code deterministically, but the crazy part here is that it doesn’t require you to change a single line in your code.
It does this by binary rewriting at test time, which injects code to allow Coyote to take control over the task scheduler. Here’s an example of a rewriting pass which I found to be easily understandable:
// https://github.com/microsoft/coyote/blob/20a461738abb16d595def740fc486c9071a9cbab/Source/Test/Rewriting/Passes/Rewriting/CallSiteExtractionRewritingPass.cs#L14-L50
/// Rewriting pass that injects callbacks to the runtime for extracting call-site information.
/// </summary>
internal sealed class CallSiteExtractionRewritingPass : RewritingPass
{
/// .... removed some boilerplate here
/// <inheritdoc/>
protected override void VisitMethodBody(MethodBody body)
{
if (this.IsCompilerGeneratedType || this.IsAsyncStateMachineType ||
this.Method is null || this.Method.IsConstructor ||
this.Method.IsGetter || this.Method.IsSetter)
{
return;
}
// Get the first instruction in the body.
Instruction nextInstruction = body.Instructions.FirstOrDefault();
// Construct the instructions for notifying the runtime which method is executing.
string methodName = GetFullyQualifiedMethodName(this.Method);
Instruction loadStrInstruction = this.Processor.Create(OpCodes.Ldstr, methodName);
TypeDefinition providerType = this.Module.ImportReference(typeof(Operation)).Resolve();
MethodReference notificationMethod = providerType.Methods.FirstOrDefault(m => m.Name == nameof(Operation.RegisterCallSite));
notificationMethod = this.Module.ImportReference(notificationMethod);
Instruction callInstruction = this.Processor.Create(OpCodes.Call, notificationMethod);
this.Processor.InsertBefore(nextInstruction, this.Processor.Create(OpCodes.Nop));
this.Processor.InsertBefore(nextInstruction, loadStrInstruction);
this.Processor.InsertBefore(nextInstruction, callInstruction);
During each execution, Coyote tries to find different execution paths through different strategies and generates reproducible traces for the ones which reports bugs. These are the different strategies used (but there might be more):
// https://github.com/microsoft/coyote/blob/20a461738abb16d595def740fc486c9071a9cbab/Source/Core/Runtime/Scheduling/OperationScheduler.cs#L11-L18
using BoundedRandomFuzzingStrategy = Microsoft.Coyote.Testing.Fuzzing.BoundedRandomStrategy;
using DelayBoundingInterleavingStrategy = Microsoft.Coyote.Testing.Interleaving.DelayBoundingStrategy;
using DFSInterleavingStrategy = Microsoft.Coyote.Testing.Interleaving.DFSStrategy;
using PrioritizationFuzzingStrategy = Microsoft.Coyote.Testing.Fuzzing.PrioritizationStrategy;
using PrioritizationInterleavingStrategy = Microsoft.Coyote.Testing.Interleaving.PrioritizationStrategy;
using ProbabilisticRandomInterleavingStrategy = Microsoft.Coyote.Testing.Interleaving.ProbabilisticRandomStrategy;
using QLearningInterleavingStrategy = Microsoft.Coyote.Testing.Interleaving.QLearningStrategy;
using RandomInterleavingStrategy = Microsoft.Coyote.Testing.Interleaving.RandomStrategy;
Coyote is really neat. I love the less-intrusive approach of code injection, but it’s a bummer that it’s only available for C#.
Madsim ¶
Magical Deterministic Simulator (Madsim) is a deterministic simulator for Rust programs, which follows the same concept as others by utilizing a PRNG (Pseudo-Random Number Generator), a task scheduler, and network/disk simulators which removes the sources of non-determinism from the environment.
To provide deterministic time, it tries to override the libc gettimeofday function:
// https://github.com/madsim-rs/madsim/blob/main/madsim/src/sim/time/system_time.rs#L6-L21
unsafe extern "C" fn gettimeofday(tp: *mut libc::timeval, tz: *mut libc::c_void) -> libc::c_int {
// NOTE: tz should be NULL.
// Linux: The use of the timezone structure is obsolete; the tz argument should normally be specified as NULL.
// macOS: timezone is no longer used; this information is kept outside the kernel.
if tp.is_null() {
return 0;
}
if let Some(time) = super::TimeHandle::try_current() {
// inside a madsim context, use the simulated time.
let dur = time
.now_time()
.duration_since(SystemTime::UNIX_EPOCH)
.unwrap();
tp.write(libc::timeval {
tv_sec: dur.as_secs() as _,
tv_usec: dur.subsec_micros() as _,
});
// more code ....
They also seem to have took some inspiration from FoundationDB by using BUGGIFY macros for triggering fault injection.
But once again, this can only be used Rust-based projects, but I like the patches made to std API functions which helped them to achieve determinism.
Antithesis ¶
And finally, Antithesis. The most exciting one on this list.
The reason why Antithesis is gaining so much popularity is due to the fact that you can test almost any application deterministically through their platform with minimal changes. This is a great improvement over existing solutions, which are bound to a single language/runtime.
It’s made possible by their proprietary deterministic hypervisor7, which ensures that any code which is non-deterministic in nature, can be made deterministic by running it inside the hypervisor.
Their hypervisor is built on top of the bhyve hypervisor with lots of changes made to the core to make it deterministic. I recommend reading their blog post to know about the challenges they faced while building it. It’s an impressive piece of work, and it’s definitely worth the years of effort they’ve put in.
The simulation environment consists of the system under test packaged as a set of containers, along with the workload, running on the virtual machine managed by the deterministic hypervisor.
For finding bugs, they have a “software explorer” which tries to actively find new and interesting execution paths (or, more formally, branch exploration) by exploring the state space efficiently through some guided fuzzing, and by injecting faults through a fault injection framework.
So, to summarize, they seem to follow the same pattern of setting up a deterministic environment (PRNG, mocked I/O, network, etc.) and using fault injection and intelligent fuzzing to explore the state space efficiently to find bugs. But the real differentiator is their deterministic hypervisor, which is a hard one to replicate in my opinion.
Facebook/Meta tried to do a similar thing previously through Hermit, which is a project to execute programs inside a deterministic sandbox, made possible by Reverie, which is used for syscall interception. But Hermit seems to be in maintenance mode, so I’m not sure about its future.
Other components like the “software explorer” also seem to be the shiny parts that make Antithesis a lucrative option, as I assume that their state space exploration is a bit unique (or performant) as compared to modern fuzzing techniques, but I could be completely wrong here, and maybe it’s a good mix of modern and traditional search techniques.
Since Antithesis is a paid product [$], I don’t have much information on its internals, so I can’t speak much about it. And it’s likely that they won’t reveal their secret sauce soon, but I appreciate them for dropping some really interesting demos!
Time to design! ¶
So far, I’ve talked about a few approaches to deterministic simulation testing above, but it’s time to represent the design I have in my mind for this project.
Openthesis8 borrows design decisions from the previously discussed systems. Here’s the rough, initial architecture diagram for the project (click to enlarge):
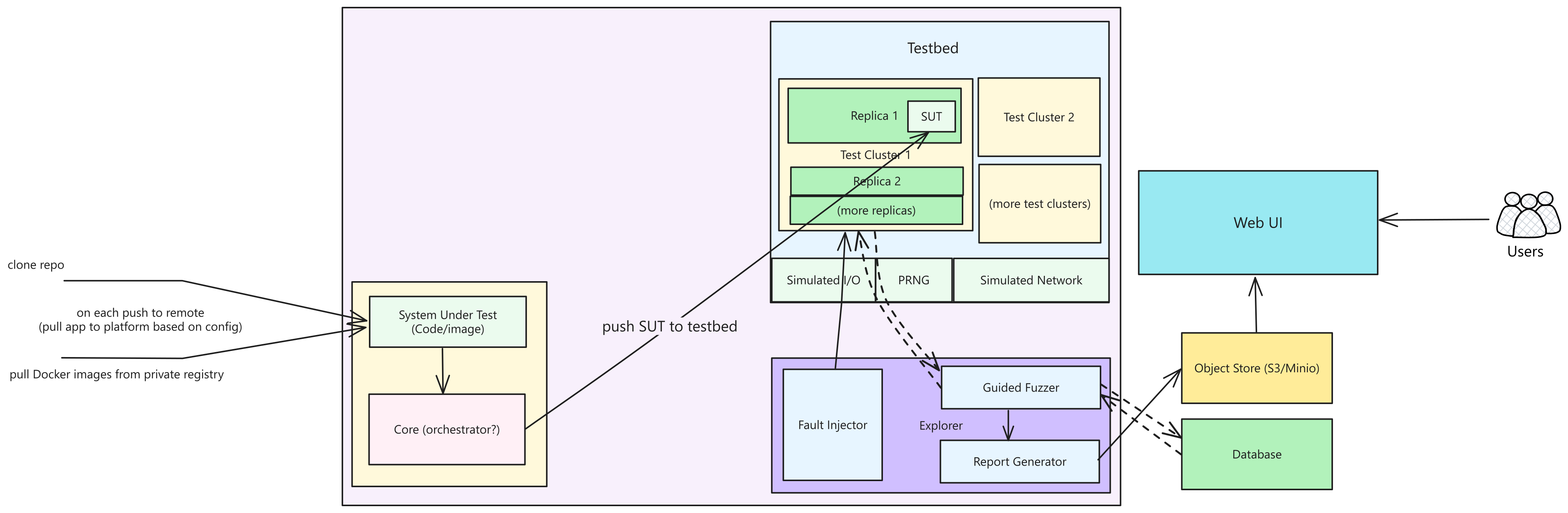
The system consists of several parts:
- The “core”: This is the central orchestrator responsible for setting up clusters based on the workload provided. The workloads are a part of the code, or would be readable inside the container. This is inspired by the FoundationDB approach of testing different scenarios through different workload configurations.
- The “explorer”: This piece is responsible for efficient state space exploration. It consists of a “guided fuzzer”, a fault injection tool, and a report generator.
- For the “guided fuzzer”, I’m thinking of utilizing coverage-guided fuzzers like libFuzzer (and maybe even AFL++ and syzkaller?).
- The fault injection tool will assist in the exploration process and its intensity would be tunable through configuration files.
- The report generator will receive the interesting bugs found by the guided fuzzer throughout the simulation’s lifetime and store them in an object store or a database for further processing.
- Testbed: This is the deterministic hypervisor where all sources of non-determinism are removed. This is based on Antithesis’ approach, as I’d want this project to be able to test almost all kinds of applications. A huge undertaking though.
Here’s what’s not covered in the diagram:
- Code-driven fault-injection: It would be nice to support
BUGGIFY-style fault-injection through code, but that would require maintaining SDKs for a few languages. It might be doable, but I haven’t thought about it much right now. - Time travel and snapshots: I’ve looked at the rr project previously, and I’m interested to see how time-travel debugging fits in this picture. But to make this work, VM snapshotting should be quick enough too. I believe I’ll get answers to these questions once I explore more about building deterministic hypervisors.
Conclusion ¶
Here’s the project’s repository. No code yet, but I’ll add a few more design documents (or notes) over the next few weeks.
In part 2, I’ll try to explain a few more things like time-travel debugging (rr project 9, etc.), guided fuzzing, and most importantly, how do I want to approach the gigantic task of trying to build the deterministic hypervisor. It’s going to be a real challenge, but I’m excited! And I’m open to any type of contributions: discussions related to design decisions, code, etc.
I’ve intentionally kept the details short for some sections (TigerBeetle, etc.) and I didn’t cover others (Resonate, Dropbox’s randomized testing of Nucleus, and PolarSignals’ WASM-based (mostly) DST) as this post was getting a bit verbose. I recommend checking them out for more details.
If you liked this, please email or tweet me with questions, corrections, or ideas! And if you’re working at Antithesis or similar companies, please do let me know your thoughts!
- However, it’s completely dependent on the implementation. A mock may even slow things down. ↩︎
- Based on the “getting started” section in the documentation. ↩︎
- Well, not really, as there are a few more steps before it reaches there. ↩︎
- Alex Miller (ex-FoundationDB) has a great blog on it. ↩︎
- They put it inside a browser, and that went viral to some extent on social media. It’s a fun way to showcase the VOPR. ↩︎
- Based on my exploration on GitHub, but I might be wrong here. ↩︎
- They do claim to make the hypervisor open source, but I’m not sure if they’d ever do it. ↩︎
- Openthesis = open-source Antithesis. If you have a better name, please suggest one on the repository! ↩︎
- rr is much more than a time-travel debugger, it also helps in providing deterministic simulation for arbitary processes. ↩︎